
cells as computers
What makes a computer and how do cells fit this model? Wang and Gribzkov (2005) describe the parallels between cells and classical computers, exploring computers as a model for biological function.

What makes a computer?
A model of computation includes inputs, outputs, and an algorithm that turns the inputs into outputs. There are many models of computation, each defining its own fundamental rules about the operations and capabilities of a computer. These abstract models can be implemented in all kinds of physical systems, including cells.
In their 2005 paper, Degeng Wang and Michael Gribzkov compare the ways in which information is utilized by cells and classical computers. They divide information utilization into two main blocks:
Information organization
Information utilization (which is further subdivided into)
Information specification: selecting the type and location of information needed for a particular action (for example, an external input or a piece of information stored in the system)
Information retrieval: retrieving the specified information and transmitting it to the computing machinery
The computing process: executing the action
While cells perform many functions, Wang and Gribskov focus on how cells use DNA-encoded information to respond to environmental signals. (Other cell-specific functions like replication are not discussed.)
It is also important to note here Wang and Gribskov’s definition of a cell: “the smallest structural unit of an organism that is capable of autonomous system integrity and functionality in a changing environment, with no dependence on an external source for architectural components.” While there are many types of cells, one important commonality is that they all operate based on information encoded in DNA.
Why try to think of cells as computers?
Existing parallels:
Code: Computers and cells are both highly complex systems that rely on surprisingly simple code. Like computers, which use binary code, cells rely on a simple quadruple genetic code (the four DNA bases: A, T, C, and G) that dictates their operation.
Hierarchical organization:
Silicon computers and cells both function at multiple levels. In a cell: at the single-gene level (individual genes store information corresponding to individual regulatory events) vs. at the cellular level (where a behavior might be produced as the result of coordinated actions by several genes). In a computer: instruction-level (ex. adding two numbers) vs. process-level (ex. searching for a number in a list) behavior. For both computers and cells, there are “multiple layers of actions before the primary genetic code [or machine code, resp.] gets translated into cellular behaviour [or computer function, resp.].”
Information is also stored in levels. Computers have hierarchical memory units: higher-level units store small amounts of data that can be quickly accessed, while lower levels contain more data (at the cost of a slower access time). Similarly, cells use RNA as a high-level memory unit and DNA as low-level memory (more on this later).
Viewing cells through the framework of classical computing enables us to better understand cellular function.
Biology research has historically used simple model organisms to understand biological processes. For example, yeast, a simple eukaryote1, is often used to study functions observed in higher-level eukaryotic species. Using the classical computer as a model system allows us to sort what we know about cellular function into an organizational framework.
We have a complete knowledge of the architecture and operation of a classical computer, but only an elementary understanding of this in cells. Given the parallels listed above, this comparison might help us better understand computation in cells.
Cells as computers
The major pieces of a classical computer are a processing unit (central processing unit or CPU), a memory unit, and a way of receiving inputs and transmitting outputs (Figure 1). As previously mentioned, computers typically have hierarchical memory. The secondary or lower-level memory stores all of the computer’s information: data and instructions. When a program runs, relevant data and instructions are loaded into primary memory, from which they are accessed by the CPU.
Cells can be represented similarly, with DNA acting as the secondary memory and RNA as the primary memory unit. When a cell needs to execute a particular function, relevant genes are loaded into the RNA space via transcription. When the RNAs are translated into proteins, they form a network of proteins that regulate each other’s production, causing the cell to behave in a particular way.
Just as a computer program receives and provides information to its user, cells interact with their environment via biomolecular signals.
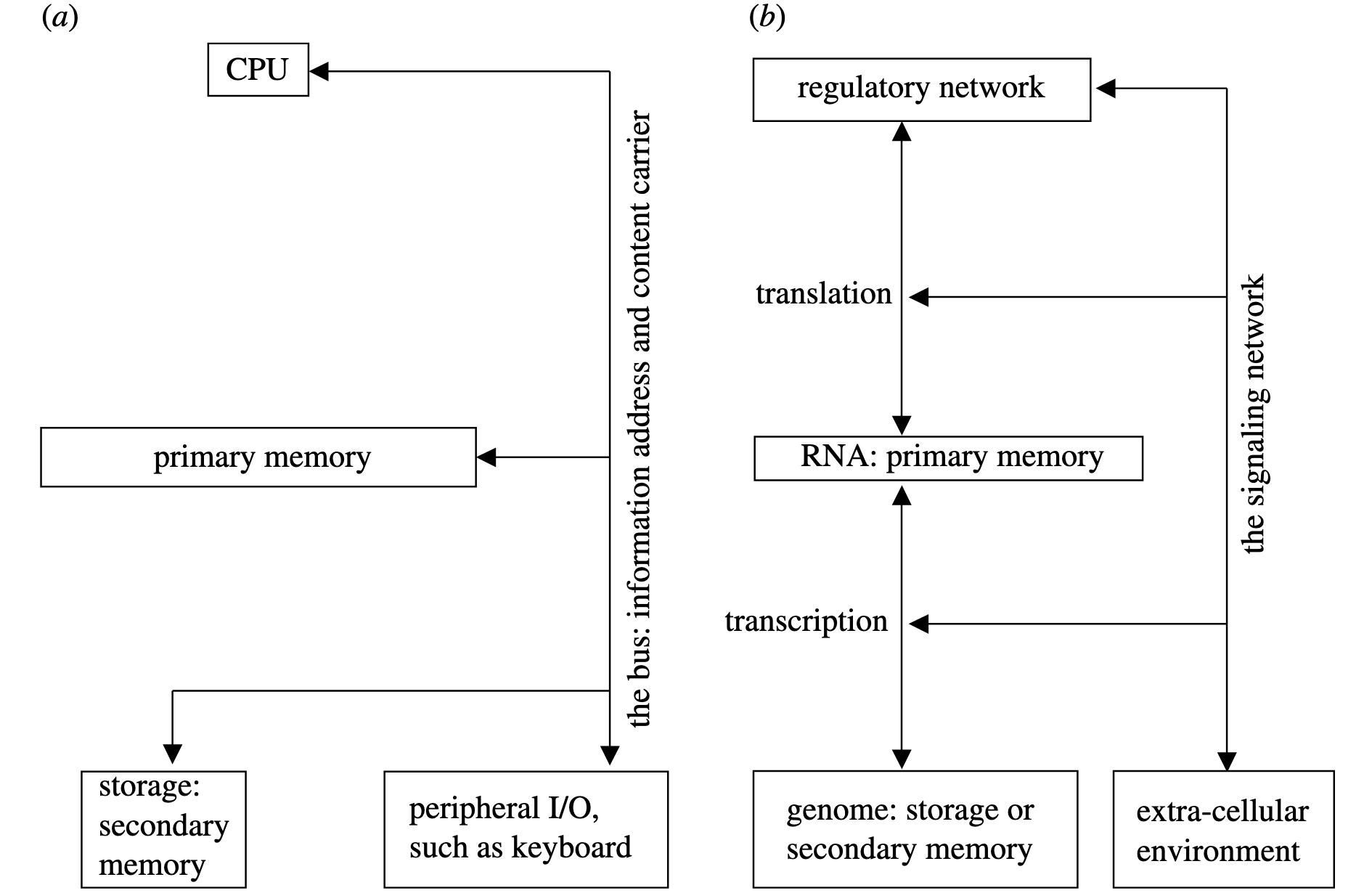
Figure 1. Basic schematics of the architecture (a) of a computer and (b) of a cell (Figure 2, Wang and Gribskov 2005). Note: Some simplifications are made in Figure 1(b), particularly with regard to the regulatory network and how exactly genes regulate each other.
Where do cells differ from classical computers?
Hardware/software boundary
In a classical computer, hardware refers to the physical components of the computer (CPU, memory, keyboard, etc.) while software is the set of instructions provided to the computer. In cells, enzymes (proteins that catalyze reactions) are analogous to hardware, while genes, which contain instructions for cellular behavior, are treated as software. However, the structure and function of these enzymes is encoded in the genes, so modifying the software also causes changes to the hardware. (Compare this to a classical computer, in which changing the software changes the behavior of the computer but not its constituent hardware.)
Signal type
Cells take biomolecular signals as input (i.e. concentrations of specific molecules inside and outside the cell), while silicon computers use electrical signals. Biomolecular signals are not discrete and usually noisy, so it is generally more difficult to perform logical operations on them as we do with digital signals in classical computers.
Massive parallelism
Information retrieval (i.e. loading information from DNA into the RNA space) is a completely parallelized process. While in a classical computer each piece of information would have to be loaded individually (assuming there is only one unit capable of doing this), cells, by nature, have plenty of units to perform this function. Transcription of all necessary genes can happen completely in parallel. Similarly, translation of the RNAs into proteins also happens in parallel, making for completely parallel instruction execution.
… and these differences could make cells more effective than classical computers at solving certain problems (read about this in a future post), although the search is still on for a ‘killer application’ in which cellular computing would vastly outperform classical methods.
Concluding thoughts
2 major themes: serial vs. massively parallel operations and a distinct vs. blurred line between hardware and software.
We are still far from a systematic understanding of how genetically-encoded information governs cellular function. Making a comparison between cells and classical computers allows for some clarity about how cells function, but doesn’t account for cell-specific characteristics like their ability to replicate (to be discussed in later posts!) that might offer advantages over classical computers.
Find the paper here:
Wang, D., & Gribskov, M. (2005). Examining the architecture of cellular computing through a comparative study with a computer. Journal of the Royal Society Interface, 2(3), 187–195. https://doi.org/10.1098/rsif.2005.0038
[definition] eukaryote: an organism with a membrane-bound nucleus (vs. prokaryotes, which do not have a defined nucleus (among other differences))